
前言
在生活充滿網路應用的今天,我們每一次點擊的背後可能都是個龐大且複雜的系統,像是搶票系統如何確保大家可以有效率地搶到票,而且不會重複販售同一張票,或是銀行系統如何確保你的餘額,不會因為連到不同的機房就顯示不同的數字等等,這些系統為了同時服務大量的客戶,都需要仰賴分散式系統以突破單機的瓶頸。
到了近十年,分散式系統已經打破組織的邊界,2009 年第一條區塊鏈問世,從此開始個人與個人之間的分散式體系;2016 年,區塊鏈更進一步突破組織間的藩籬,企業與企業之間的聯盟鏈開始蓬勃發展。區塊鏈的出現為分散式帶來了更多挑戰,但不管這些基於分散式的應用如何改變,還是都離不開分散式系統的理論框架 — CAP 定理(Consistency-Availability-Partition Tolerance theorem)。
CAP 定理勾勒出分散式系統天生上的限制,透過 CAP 定理我們可以理解為什麼共識機制如此複雜,以及系統如何在強一致性與最終一致性間做取捨。本篇會從分散式系統的挑戰開始,介紹 CAP 定理,以及 CAP 中的三元取捨,希望讀者閱讀後可以對分散式系統有個思考框架。
本系列會從介紹 CAP 定理開始,介紹一系列分散式相關的算法,像是 Raft, Gossip, Quorum NWR 等等,也歡迎讀者在留言區分享你認識的分散式算法,互相交流!
分散式有多難?
不管設計什麼架構,我們都希望滿足高性能且高可用的系統,為了突破效能的瓶頸,我們從單核走向了多核,從單機走向了多機;為了防止意外造成系統無法運作,我們透過「備餘」來對抗各種天災人禍。分散式的目的就在於突破單機的效能瓶頸並建立不間斷的服務,而分散式設計帶來的好處,恰恰也是分散式設計的困難點。
試想一個情境,我們使用了某銀行的行動支付轉帳給朋友,恰巧就在此時,因為某個路段在修路把銀行台北機房對高雄機房的光纖網路挖斷了,造成台北機房已經有這筆轉帳記錄,但高雄沒有(如圖一),雪上加霜的是,此時台北機房對外的網路也意外被切斷了,所以使用者查看轉帳結果時,被導向了高雄機房,造成使用者以為轉帳沒有成功再轉了一筆(如圖二),最後光纖網路修復後,使用者才發現原來有兩筆轉帳的紀錄(如圖三)。上述情況只是分散式可能面臨的其中一種情況,就算網路線沒有被挖斷,系統還是會因為網路延遲造成資料短暫的不一致,現實中有各種不同的意外要應付,此時如果我們有一個可以幫助我們思考分散式系統的思想框架,將會有助於我們設計分散式系統。

圖一:A 透過台北機房匯錢給 B
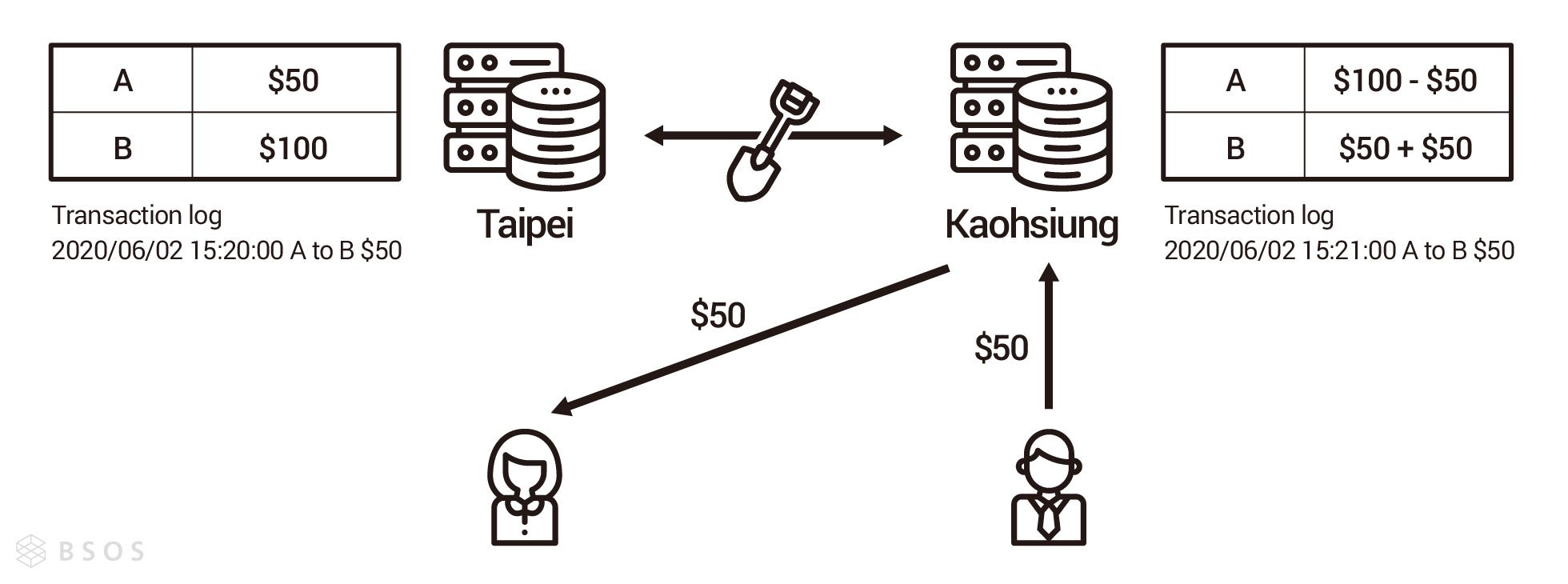
圖二:A 透過高雄機房匯錢給 B
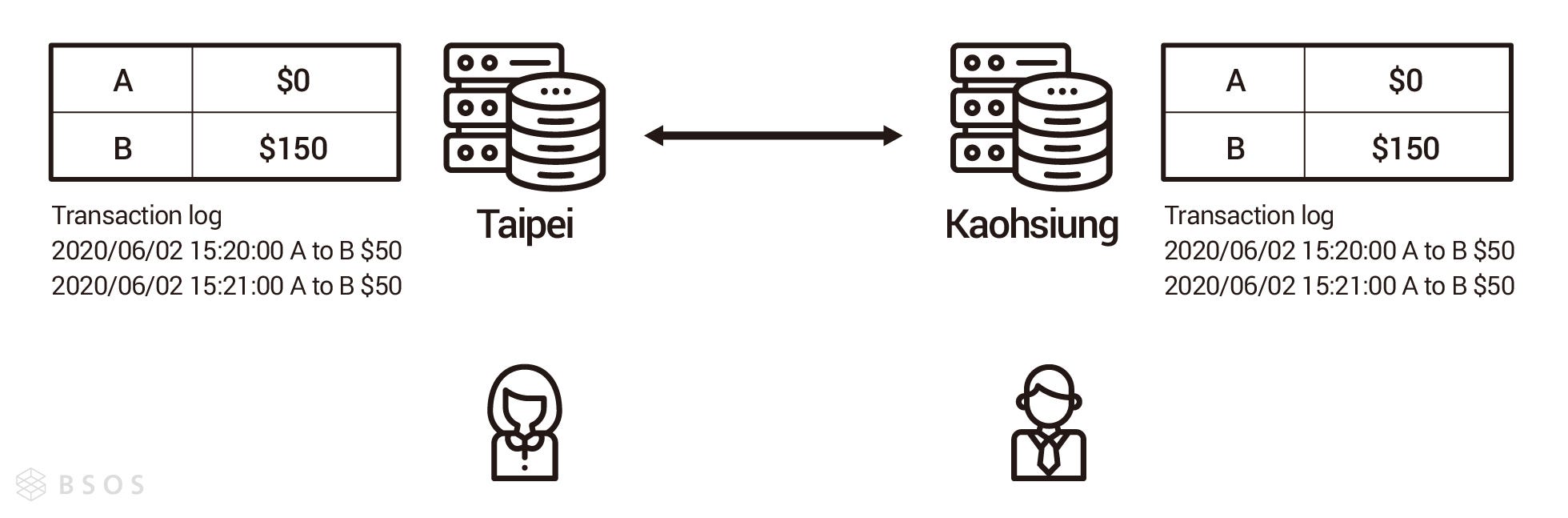
圖三:節點之間連線修復
分散式的思考框架 — CAP 定理介紹
Eric Brewer 最早於 1998 年有 CAP 理論的構想,在 2000 年的 PODC 會議上發表這個猜想,2002 年時由 Seth Gilbert 及 Nancy Lynch 證實了這個猜想,因此 CAP 定理(CAP theorem)又被稱作 Brewer’s theorem。
CAP 定理由一致性(Consistency)、可用性(Availability)及分區容錯性(Partition tolerance)組成,不過由於作者當初提出時,並沒有給這三者明確的定義,因此不同的人對於 CAP 的定義有些分歧,像是 IBM Cloud 上的定義跟 Wiki 的就有些出入。這裡我們使用 Robert Greiner 給的定義,不過光是 Robert Greiner 就定義過兩次 CAP,這裡我們選擇新的定義解釋,因為作者已經把舊的定義標上 Outdated 了,讀者可以自行比較兩次定義的差異。
CAP 定理
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance — one of them must be sacrificed.
首先 Robert 定義適用於 CAP 定理的系統,這個系統必須是一個分散式系統,不過分散式系統有很多種,像是有些系統只涉及分散運算,但不涉及資料保存,而有些系統則是兩者都有,因此作者特別表明是要有「共享資料」的分散式系統。在這個系統內依據 CAP 定理,我們的每一次讀寫頂多只能滿足 Consistency、Availability 或是 Partition Tolerance 三者中的兩個。後面我們會在說明為什麼只能滿足其中的兩項,這裡我們先看定義。
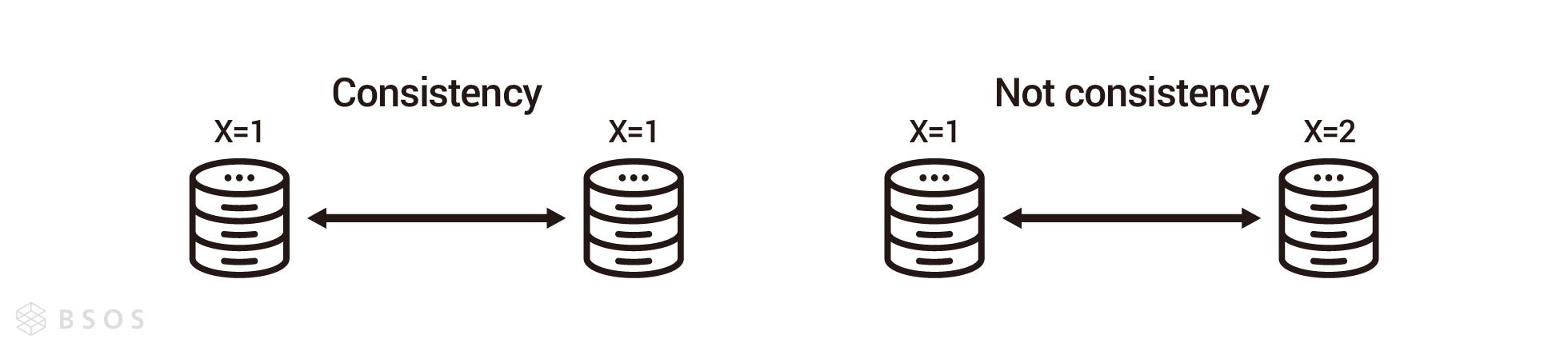
Consistency
A read is guaranteed to return the most recent write for a given client.
對於一致性,Robert 的定義是:系統必須保證客戶端的讀操作會取得最近更新的資料。作者選擇從用戶的角度而不是從系統的角度描述,原因是每一次事務(Transaction)發生的過程,系統都處於不一致的狀態,所以從系統的角度看,系統是不可能隨時持一致性的。從用戶的角度,我們可以透過一些設計,像是 Quorum NWR,每一次用戶讀取都至少從 R 個節點讀取,並從中選出最新的資料回傳,以此來達成對用戶的一致性。
Availability
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
對於可用性,Robert 的定義是:一個健康的節點必須在合理的時間內回傳合理的回應。作者使用「合理的」而不是「正確的」來描述回應,原因是系統會面臨各種不能控制的風險,但只要系統設計合宜,在意外發生的情況下還是可以給出合理的回應,那這個系統就具有可用性。
Partition tolerance
The system will continue to function when network partitions occur.
對於分區容錯性,Robert 的定義是 — 在網路分區的情況下,系統依然能夠繼續運作。在網路發達的今天,我們的手機幾乎隨時都處於連線的狀態,所以網路分區對一般用戶比較難想像。對機房來說,不同機房之間的連線通常是用專門的網路線,為了確保機房的網路穩定及安全性,這些網路線是不對外公開的,如果這些網路線如果被挖斷,對於機房來說,等於機房跟機房之間的網路就斷了,所以機房與機房就會產生分區,而在分區的情況下,不同的機房還是可以對外繼續運作的能力,就叫分區容錯性。在實際設計上,分區容錯代表的不僅是分區的情況下還要繼續運作,還包括連線恢復後,如何同步及修正兩個分區的資料差異,才算完整的達到分區容錯性。

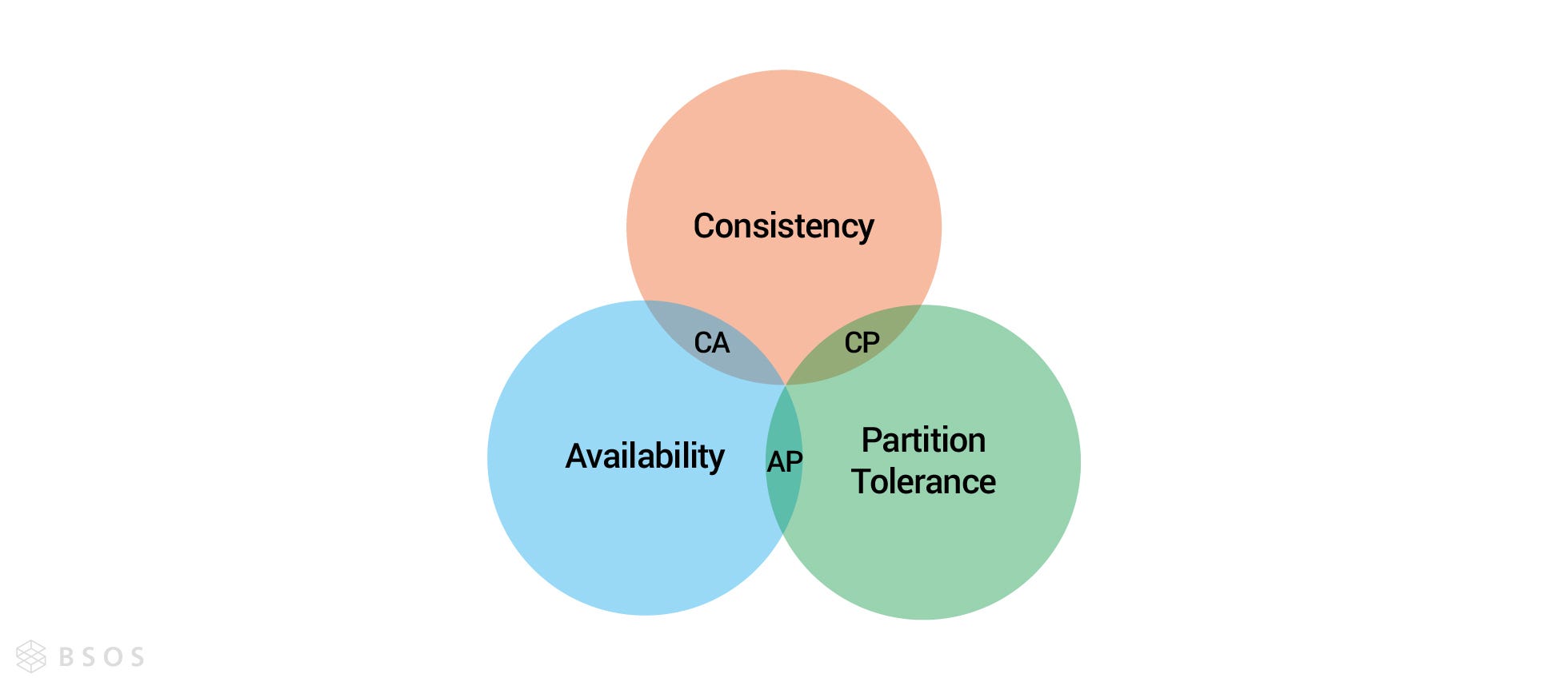
分散式的不可能三角 — CAP 三元取捨
CAP 定理乍看之下,三個任取兩個都可以,但在現實世界中,網路是最無法被保證的,所以分區容錯性(P)是一定要被保障的,所以實際設計系統時,我們要在一致性(C)跟可用性(A)之間做取捨。
強一致性 — CP 與 ACID

ACID 是關連式資料庫的基石,代表每次事務(Transaction)需要滿足原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)及持久性(Durability)。CAP 定理是對於系統的描述,而 ACID 是對於事務(Transaction)的描述,雖然兩種對於不同層面描述的理論不應該被放在一起討論,但這裡想強調的是 ACID 是強一致性的描述,如果在分散式情況下滿足了,也等於滿足了 CP 模型。
分散式要在系統層面滿足強一致性,通常會使用兩階段提交(Two-Phase Commit, 2PC),通常步驟如下:
- 使用者向協調者(Coordinator)發起一個寫操作
- 準備階段(Prepare Phase): 協調者向其他所有節點詢問是否可以進行此操作
- 執行階段(Commit Phase): 若所有節點皆回覆可以執行操作,則協調者向所有節點發送執行此操作
設計兩階段提交時要注意,在準備階段(Prepare Phase),節點如果回覆「允許」進行操作,那麼不管發生什麼意外,節點都要能保證在執行階段(Commit Phase)進行此操作,即使準備階段後,節點因意外關機,節點也要在意外恢復後,依據協調者的指令完成準備階段答應的操作。另外因為是強一致性的關係,所以協調者會在執行階段(Commit Phase)結束才回覆使用者,因為如果協調者在準備階段(Prepare Phase)結束就回覆給使用者,那可能因為協調者還沒發送執行訊息給其他節點前,就意外關機,造成使用者接收到的訊息與整個集群不一致。

Prepare Phase
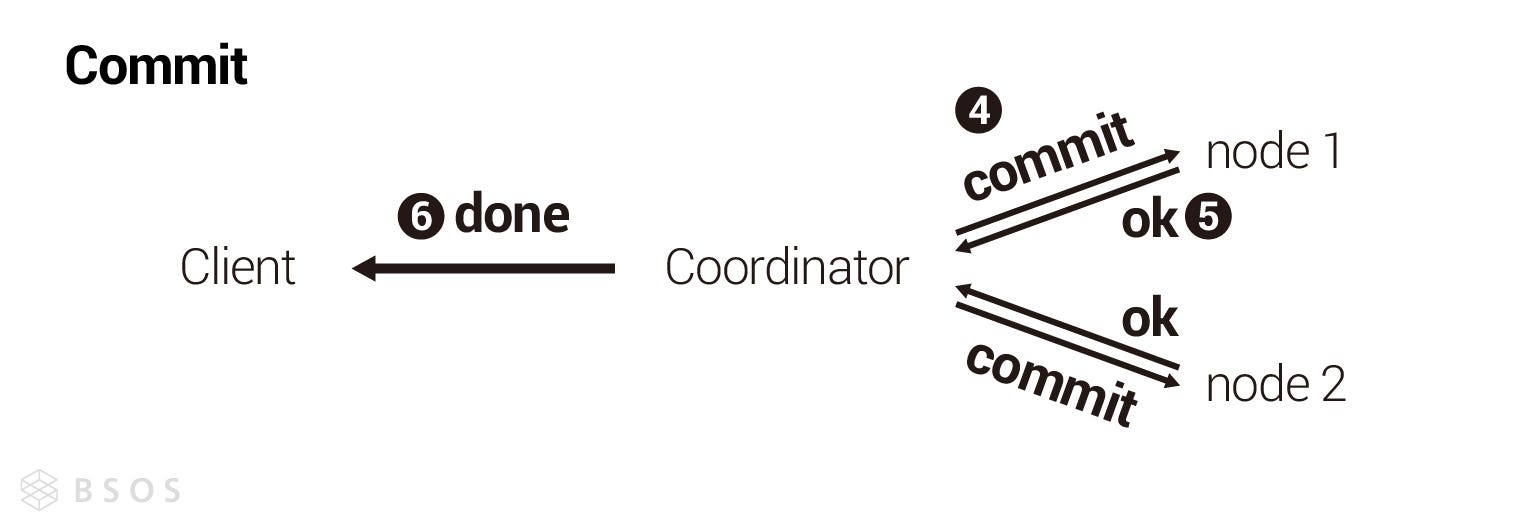
Commit Phase
兩階段操作被應用在許多分散式算法及系統中,比較出名的像是 MySQL XA、Raft 等。在更複雜的情況,像是需要拜占庭容錯(Byzantine Fault Tolerance, BFT)的區塊鏈裡,甚至還進一步使用三階段提交(Three-Phase Commit, 3PC)來防止節點作惡,詳細可以參考 PBFT。
高可用性 — AP 與 BASE
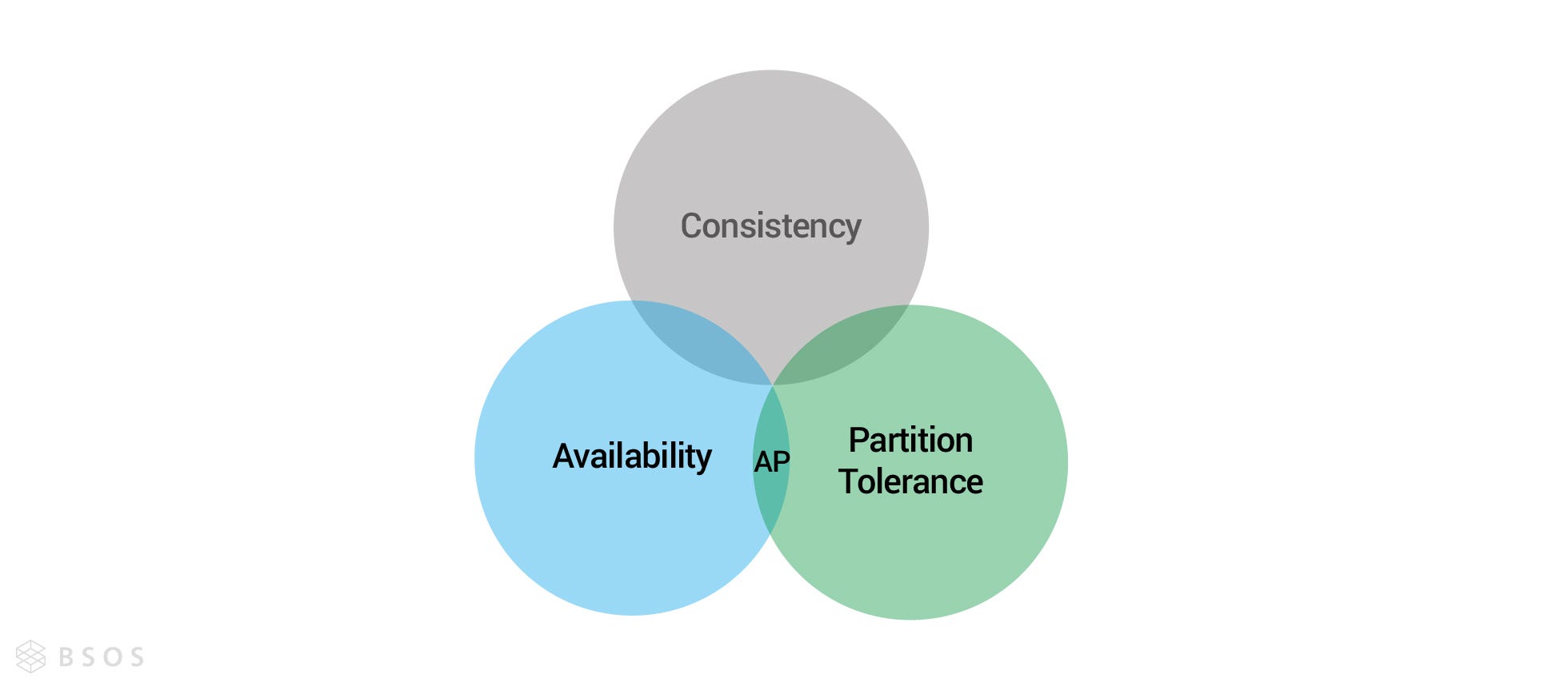
BASE 代表的是基礎可用(Basically Available)、最終一致性(Eventually Consistent)及軟狀態(Soft State),從字面意義就能發現,BASE 以可用性為主,對一致性的要求則比較低,只要最終狀態是一致性即可,所以滿足了 BASE,基本上就符合 AP 模型。
對於網路的用戶來說,如果一個系統不可用,那即使應用內部的狀態有多麼的一致,對用戶來說都是壞掉的,所以我們很常在網路應用中看到基礎可用(Basically Available)的手法,以 Facebook 按讚數為例,熱門的貼文剛發表時,就會湧入一堆人按讚,每一次按讚對系統來說都是一次寫入,如果系統為了強一致性讓一部份人暫時無法寫入的話,那大家一定會覺得是不是系統壞掉了,所以 Facebook 並不需要急著統計出一個精確的數字,因為對大多數人來說 8 個讚跟 10 個讚沒什麼區別,只要系統可以在最後保持最終一致性即可。
不過只滿足了基礎可用,系統還是要有方法可以恢復最終一致性(Eventually Consistent),常見的做法有讀時修復(Read Repair)、寫時修復(Write Repair)以及反熵(Anti-Entropy)。讀時修復在讀取時同時到多個節點讀取,並以最新的節點為主;寫時修復,同時寫入多個節點,若發現有寫入失敗則記錄下來,定時重傳,直到寫入成功,或是有新的寫入為止;最後反熵則是定期檢查狀態是否一致,如果不一致則透過特定的修復順序,修正每個節點的資料,詳細步驟會在之後講 Gossip 協議時提到。
總結
這次我們介紹了 CAP 定理,以及 CAP 定理應用的模型,如果想對 CAP 定理有進一步的認識,可以看 Eric Brewer 在 2012 年寫的文章 — CAP 定理 12 年來的回顧。使用 CAP 定理有兩個要注意的地方:
- 首先雖然系統分區(P)的情況並不常發生,但我們一定要為了分區容錯性做準備;反之在沒有分區的情況下,我們要盡力同時達成一致性跟可用性。
- 第二是雖然我們以 CAP 來描述整個系統,但其實系統內可以設計成敏感的資料滿足 CP 模型,不重要的資料則滿足 AP 模型,所以 CAP 定理是可以拉到資料層面來思維的。
最後,理解 CAP 定理是理解分散式的重要入門,更是瞭解區塊鏈共識機制的基本觀念,少了 CAP 的概念,可能只能在方法與步驟上層面上理解共識機制,但有了 CAP 的概念,則可以進一步的探討,算法如何在一致性與可用性之間做取捨。
出處:https://blockcast.it/2020/06/05/bsos-understand-cap-theorem-first-then-blockchain/




